https://321fsdw.tistory.com/48
단순회귀분석(Simple Linear Regression)
상관계수는 두 변수 간의 선형적 관계만을 검증하는 데 그치지만, 회귀분석은 독립변수와 종속변수를 설정하여 이 둘의 인과관계를 분석하는 방법이다. 단순회귀분석은 하나의 독립변수를 다
321fsdw.tistory.com
위의 글에서 단순회귀분석에서는 독립변수와 종속변수의 인과관계를 분석하는데 목적이 있다고 하였다. 다중회귀분석도 마찬가지의 논리이다. 차이점이 있다면 다중회귀분석은 독립변수가 여러 개라는 점이다.
앞서 단순회귀분석에서 우울이라는 독립변수가 종속변수인 삶의 만족도가 어떻게 변하는지에 대해 예시를 들었다. 여기에서 독립변수의 개수를 좀 더 투입시키면 다중회귀분석이 되는 것이다.
주로 다중회귀분석에 있어 주로 사용되는 변수의 선택방법은 4가지다. 독립변인 간의 다중공선성문제의 방지를 위해 사용되는 RIDGE, LASSO 방법도 있으나 SPSS에서는 사용할 수 없다. 사용하기 위해서는 R을 사용해야한다. 계량심리에 관심이 있다면 따로 찾아서 공부하길 바란다.
1. 입력방법 - 독립변수를 회귀모형에 모두 투입시켜서 분석하는 방법이다.
2. 전진선택법 - 독립변수를 하나도 포함시키지않은 상태에서, 상관관계가 제일 높은 독립변수를 선택하여, 하나씩 회귀식에 추가하는 방법이다. 다만 어떤 변수를 먼저 선택하느냐에 따라 결정계수 값에 오류가 생길 가능성이 있기에 최적의 회귀식은 추정하기 어렵다는 단점이 있다.
3. 후진제거법 - 독립변수를 모두 포함한 상태에서, 상관관계가 제일 낮은 독립변수를 제거하여 재추정하는 방법이다.
4. 단계선택법 - 위의 2가지 방법을 모두 적절하게 혼합한 방법이다. 전진선택법처럼, 하나씩 독립변수를 추가하는 과정 중에, 유의하지않는 변수가 생기면 제거하여 추가와 제거를 반복하는 방법이다.
다음은 다중회귀분석의 절차이다.

상단의 분석(A) - 회귀분석(R) - 선형(L)을 클릭한다.

각각 독립변수(I)와 종속변수(D)를 투입한다. 그 후, 방법(M)을 클릭하면 4가지방법이 나오는데, 입력은 입력방법, 전진은 전진선택법, 제거는 후진제거법, 단계선택은 단계선택법이다. 주로 사용되는 것은 입력과 단계선택방법이다. 해당 절차에서는 단계선택방법을 사용한다. 선택 후, 통계량(S)를 클릭한다.
모형적합(M)은 기본으로 설정되어 있고, R,R제곱, 수정된 R제곱 표준오차, 분산표를 알 수 있다. 여기에서 중요한 것은 공선성 진단(L)이다. 공선성진단을 통해 독립변인 간, 상관관계가 높은 변수를 찾을 수 있다.

도표(T)를 클릭하면 다음과 같은 화면이 뜬다. 여기에서 히스토그램(H)와 정규확률도표(R)을 클릭한다. 여기에서 ZPRED와 ZRESID를 선택하여 산포도를 그린다면, 이상점을 찾고, 정규성 및 등분산성 검정을 할 수 있다.

저장(S)을 눌러, 비표준화(U)에 체크를 하고 계속- 확인을 하면 결과값이 나온다.

진입과 제거가 되었다는 것은 변수의 선택방법에 따라(해당 예시는 단계선택을 사용) 회귀모형에 추가 혹은 제거가 되었음 을 뜻한다. 해당 예시에서는 회귀모형에 모두 포함되었다.
모형 요약은 각 단계에 따른 회귀모형의 설명량(R)과, 각 단계에서 투입된 독립변수의 상대적 기여도를 나타내는 R제곱 변화량 및 수정된 R제곱이 제시된다. 지난번에도 이야기했듯이 R이란 종속변인의 변화량 중 독립변인이 영향을 준 기여도의 양이라 하였다. 또한 R제곱과 수정된 R제곱은 독립변수의 개수에 따라 조절된 양이라고 설명하였다. (spss 최신판의 경우는 F변화량과 그에 따른 변화량의 유의확률도 제공하나 해당 버전은 20이기에 제공되지않았음을 참고하라.)
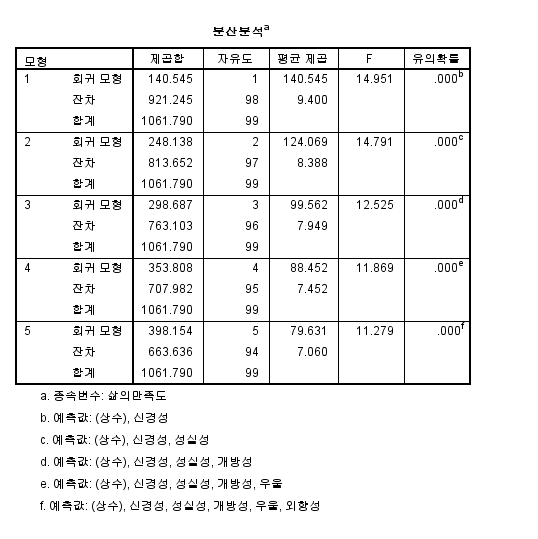
분산분석표에서는 다섯가지의 변인에 모두 투입된 최종 모형의 F값은 11.279, 유의확률은 0.00이므로 회귀모형이 최종적으로 유의하다 할 수 있다.
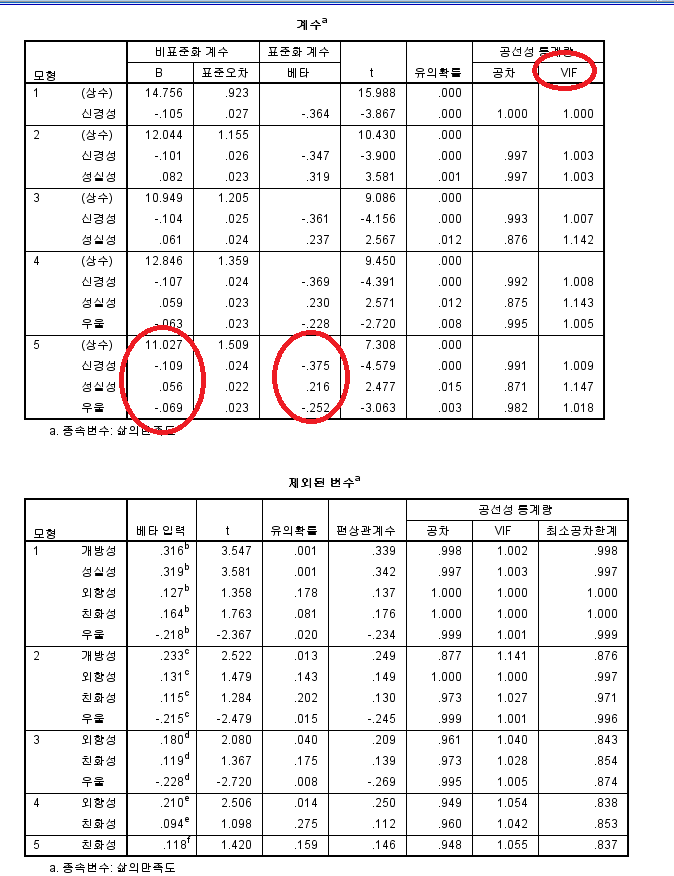
회귀계수는 표준화계수, 비표준화계수, t값 유의확률, VIF(다중공선성)의 값을 제공해준다. 다음과 같이 해석하면 된다.
| B (비표준화계수값) | 독립변인이 종속변인에 미치는 영향 | 최종모형에서 신경성, 성실성, 우울 이 3가지 요인이 삶의 만족도에 미치는 주요요인으로 나타남. |
| 베타 (표준화계수값) | 독립변인의 상대적 중요도 | 예를 들어 신경성이 -.375이 나타났으므로, 신경성이 삶의 만족도에 37.5%만큼 부정적인 영향을 주었다는 것임. |
| VIF( 다중공선성) | 독립변수 간 상관관계의 정도를 뜻함. | 1~10까지 범위이며, 낮을 수록 공선성이 낮음을 뜻함. 해당 도표에서는 1에 가까우므로 공선성이 매우 낮음을 의미함. |
제외된 변수 표는 해당 단계에서 회귀모형에 포함되지 않은 변수들의 통계적 검정 결과를 보여준다. 이 표를 통해 해당 변수들이 왜 모형에 포함되지 않았는지, 또는 이후 단계에서 포함될 가능성이 있는지를 알 수 있다.

히스토그램과 정규확률도표에 체크를 했다면, 나타나는 그래프이다. 히스토그램의 경우, 정규분포를 가정한다고 볼 수 있고, 하단의 잔차의 도표에서는 점으로 체크된 것이 직선에 일치할 수록 표준화된 잔차가 정규분포함을 나타낸다.
우울과 성격 5유형이 삶의 만족도에 미치는 영향에 대한 예시는 실제 연구에서는 사실 적절치 못하니까, 통계적인 방법이 이렇게 이루어진다. 라고 이해하면 좋을듯하다.
해당 예시의 데이터파일
'심리통계학' 카테고리의 다른 글
| 로지스틱 회귀분석(logistic regression) (0) | 2025.01.21 |
|---|---|
| 더미변수(dummy variable)란? (0) | 2025.01.20 |
| 단순회귀분석(Simple Linear Regression) (0) | 2025.01.15 |
| 편상관계수(Partial Correlation Coefficient) (0) | 2025.01.14 |
| 피어슨 상관계수(Pearson Correlation Coefficient) (0) | 2025.01.09 |



